Using deep neural networks to predict how natural sounds are processed by the brain

In recent years, machine learning techniques have accelerated and innovated research in numerous fields, including neuroscience. By identifying patterns in experimental data, these models could for instance predict the neural processes associated with specific experiences or with the processing of sensory stimuli.
Researchers at CNRS and Université Aix-Marseille and Maastricht University recently tried to use computational models to predict how the human brain transforms sounds into semantic representations of what is happening in the surrounding environment. Their paper, published in Nature Neuroscience, shows that some deep neural network (DNN)-based models might be better at predicting neural processes from neuroimaging and experimental data.
“Our main interest is to make numerical predictions about how natural sounds are perceived and represented in the brain, and to use computational models to understand how we transform the heard acoustic signal into a semantic representation of the objects and events in the auditory environment,” Bruno Giordano, one of the researchers who carried out the study, told Medical Xpress. “One big obstacle to this is not the lack of computational models—new models are published regularly—but the lack of systematic comparisons of their ability to account for behavioral or neuroimaging data.”
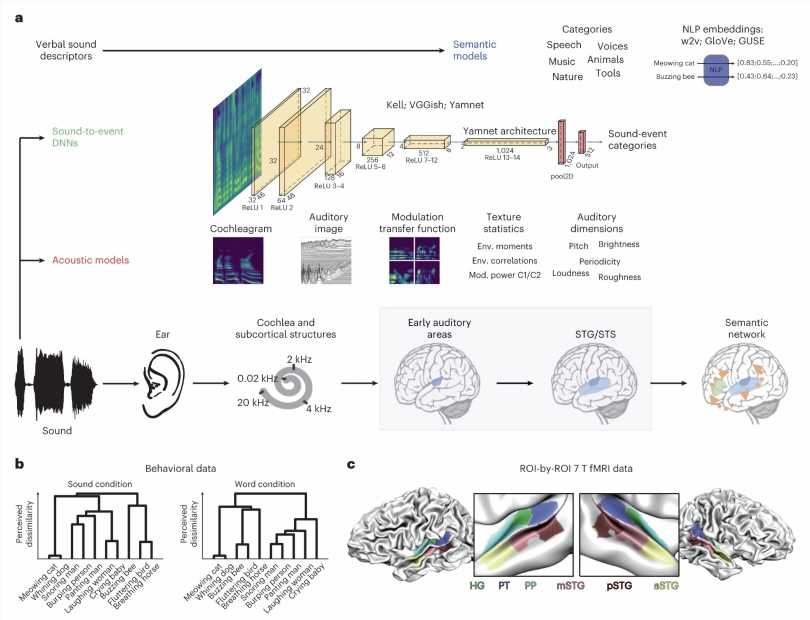
The key objective of the recent work by Giordano and his colleagues was to systematically compare the performance of different computational models at predicting neural representations of natural sounds. In their experiments, the team assessed three classes of computational models, namely acoustic, semantic and sound-to-event DNNs.
“We started talking about the need to carry out a systematic comparison of computational models during the first months of the COVID pandemic,” Giordano explained. “After a couple of remote brainstorming sessions, we realized that we already had the data we needed to answer our question: a behavioral dataset collected in 2009 with 20 Canadian participants who estimated the perceived dissimilarity of a set of 80 natural sounds, and an fMRI dataset collected in 2016 with five Dutch participants who heard a different set of 288 natural sounds while we recorded their fMRI responses.”
Without having to collect new data in the lab, the researchers thus set out to test the performance of the three computational-modeling approaches they selected using data gathered in previous experiments. Specifically, they mapped the sound stimuli that had been presented to human participants onto different computational models and then measured the extent to which they could predict how the participants responded to the stimuli and what happened in their brain.
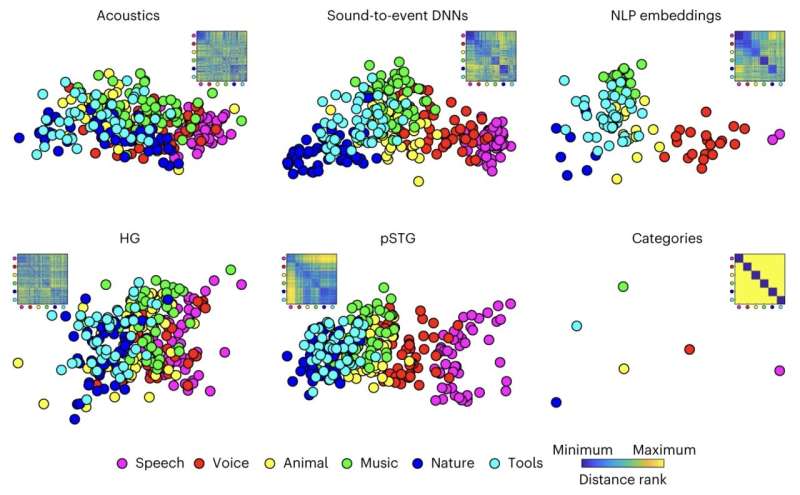
“We were stunned by the extent to which sound-to-event DNNs recently developed by Google outperformed competing acoustic and semantic models,” Giordano said. “They predicted our behavioral and fMRI data so well that by mapping sounds onto the DNNs, we could predict the behavior of our 2009 Canadian participants from the 2016 fMRI responses of the Dutch participants, even if the sounds they heard were completely different.”
Giordano and his colleagues found that DNN-based models greatly surpassed both computational approaches based on acoustics and techniques that characterize cerebral responses to sounds by placing them in different categories (e.g., voices, street sounds, etc.). Compared to these more traditional computational approaches, DNNs could predict neural activity and participant behaviors with significantly greater accuracy.
Based on their observations and the outputs produced by DNN-based models, the researchers also hypothesized that the human brain makes sense of natural sounds similarly to how it processes words. While the meaning of words is inferred by processing individual letters, phenomes and syllables, however, the meaning of sounds might be extracted by combining a different set of elementary units.
“We are now working on collecting new neuroimaging data for testing specific hypotheses that our study has put forward on what these elementary units may be,” Elia Formisano added. “We are also working on training novel and more ‘brain-like’ neural networks for natural sounds processing. For example, our co-author, Michele Esposito, has developed a neural network that learns numeric representations of verbal sound descriptors (semantic embeddings), instead of sound-event categories. This network, set to be presented at the International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2023, outperforms Google’s networks at predicting natural sound perception.”
More information:
Bruno L. Giordano et al, Intermediate acoustic-to-semantic representations link behavioral and neural responses to natural sounds, Nature Neuroscience (2023). DOI: 10.1038/s41593-023-01285-9
Journal information:
Nature Neuroscience
Source: Read Full Article


